Ausführliche Beschreibung
Ausführliche Beschreibung anzeigen
Schnelle, KI-gestützte Vokalbearbeitung
DynAssist automatisiert zeitaufwändige Gesangsbearbeitungen durch die Integration von KI und ARA. Es scannt Ihr Audiomaterial in Sekundenschnelle und schreibt die Lautstärkeautomatik auf der Grundlage Ihrer Einstellungen. Es erledigt Gain-Anpassungen, Atemkontrolle, Zischlauterkennung und Gating auf einmal und erspart Ihnen so stundenlange manuelle Arbeit. Mit KI-gestützter Präzision sorgt DynAssist für einen ausgefeilten, professionellen Sound, ohne dass Sie ständig nachjustieren müssen. Ob für Dialoge, Podcasts oder Musik, es liefert natürliche, ausgewogene Vocals mit minimalem Aufwand.
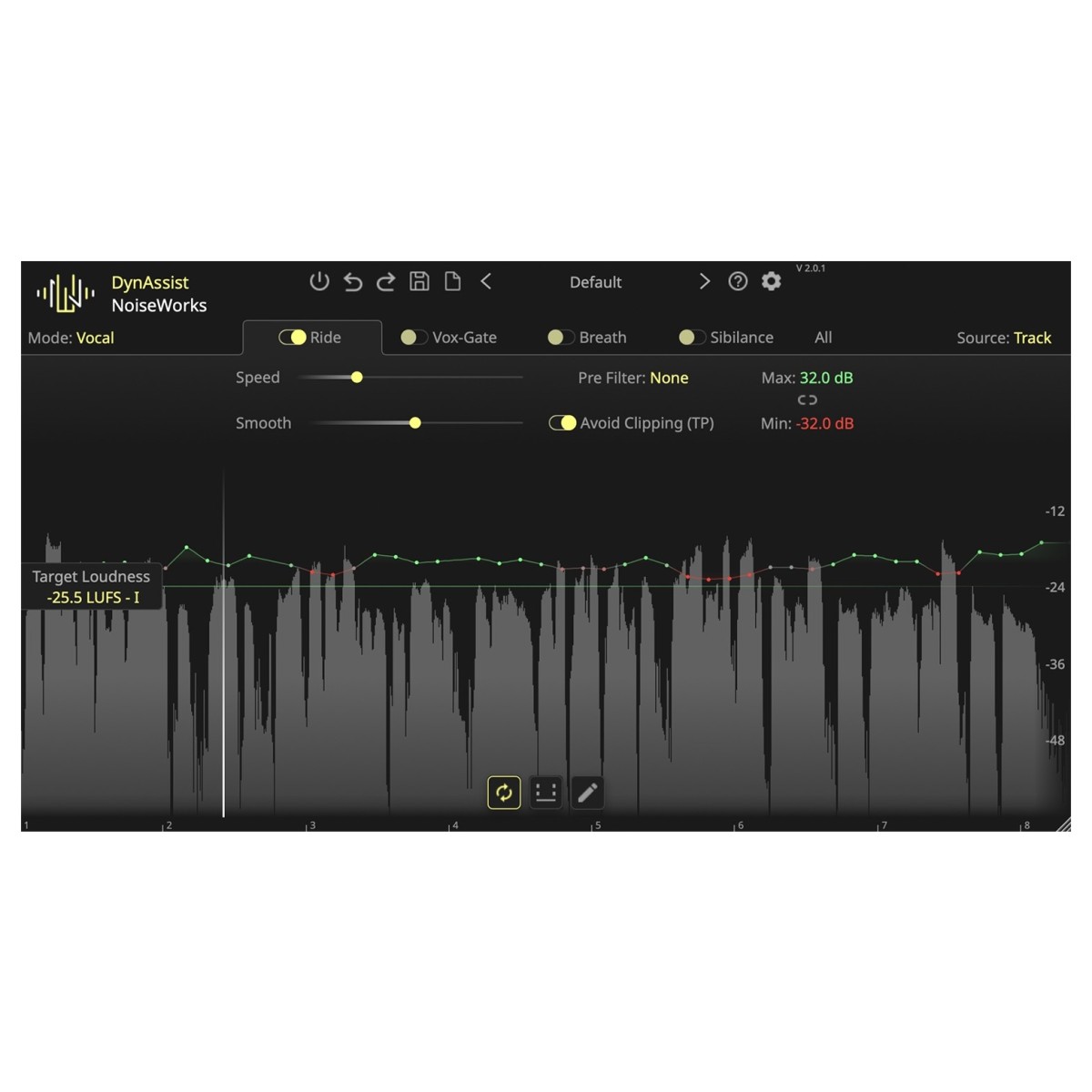
Unendliches Lookahead Vocal Riding
Im Gegensatz zu herkömmlichen Vocal Riders antizipiert die Infinite-Lookahead-Technologie von DynAssist Lautstärkeschwankungen, verhindert das Pumpen und sorgt für einen gleichmäßigen, natürlichen Klang. Es passt die Lautstärke an den gewünschten LUFS-I-Pegel an und vermeidet unerwünschte Spitzen und Einbrüche. Da die Technologie mit einer Latenzzeit von 0,0 ms und einer geringen CPU-Belastung arbeitet, erhalten Sie Echtzeitanpassungen ohne Wiedergabeverzögerungen, sodass Ihr Workflow effizient bleibt.
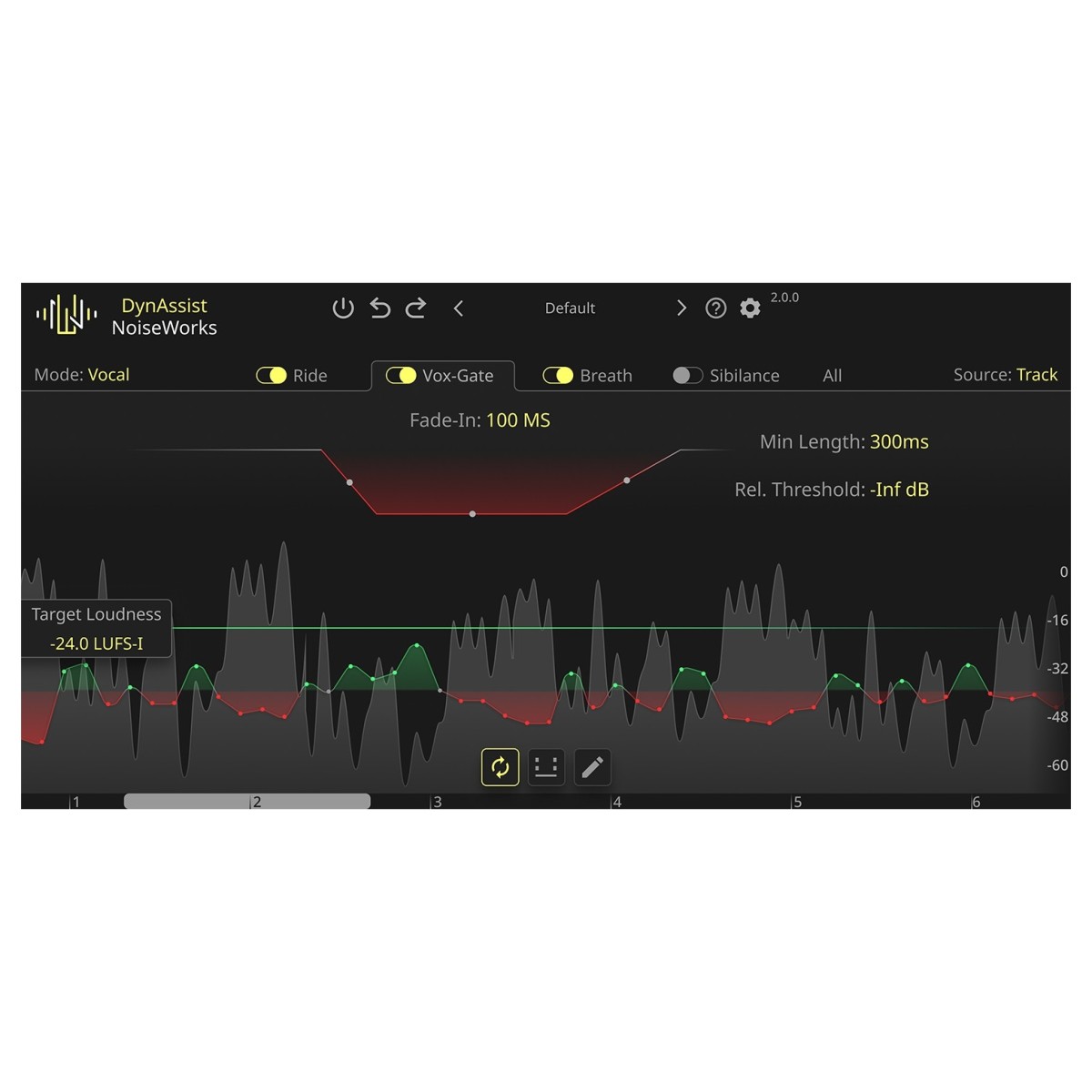
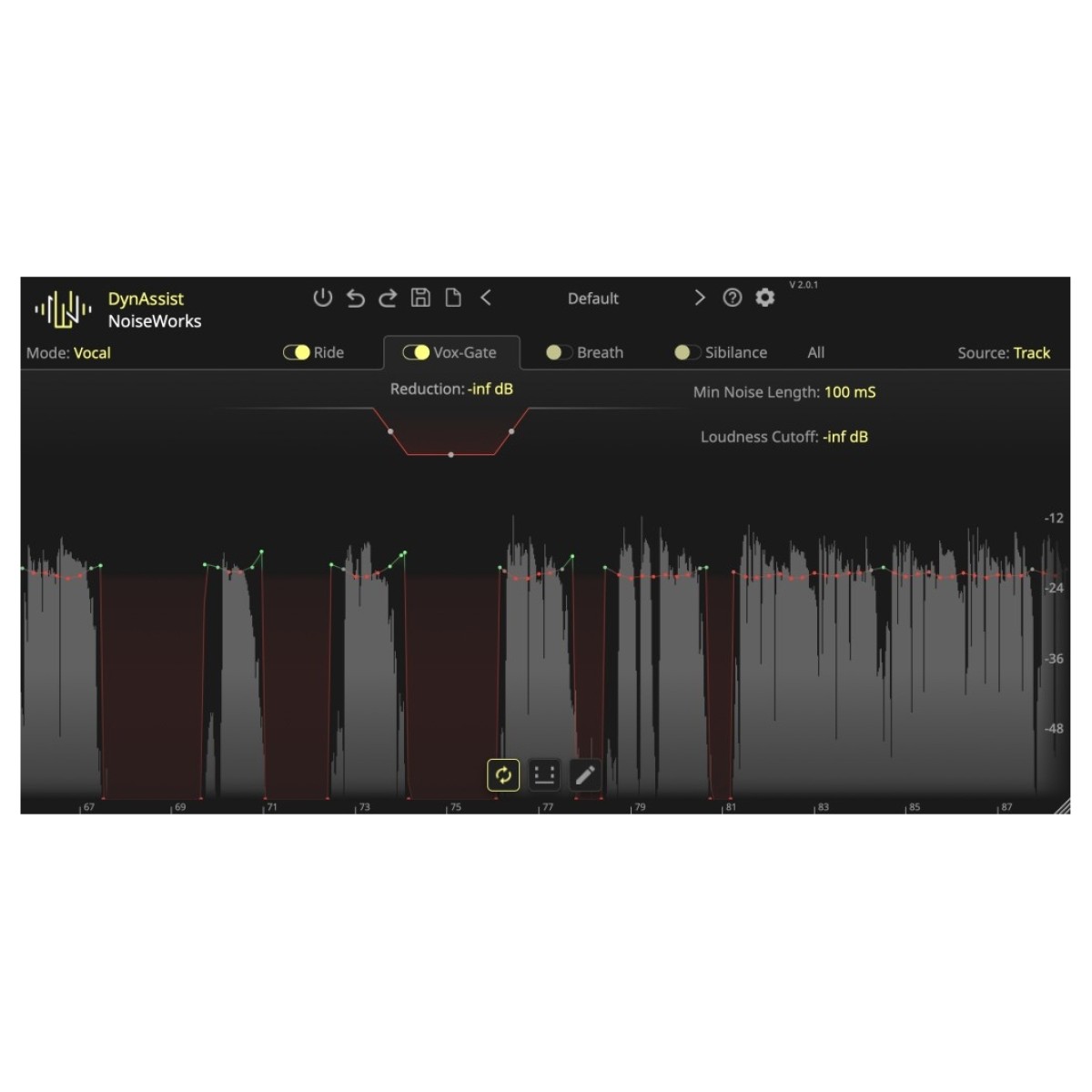
KI-gesteuertes Vox-Gate für sauberes Audio
Das KI-gesteuerte Vox-Gate von DynAssist entfernt auf intelligente Weise unerwünschte Stille, ohne dass manuelle Schwellenwertanpassungen erforderlich sind. Es erkennt die Sprachaktivität und stellt sicher, dass keine Wörter versehentlich abgeschnitten werden, was bei herkömmlichen Gates häufig der Fall ist. Für noch mehr Kontrolle funktioniert die Loudness-Cutoff-Funktion wie ein stimmbezogener Schwellenwert, der Hintergrundgeräusche und unerwünschtes Ausbluten verhindert, während Ihre Dialoge oder Stimmen intakt bleiben.
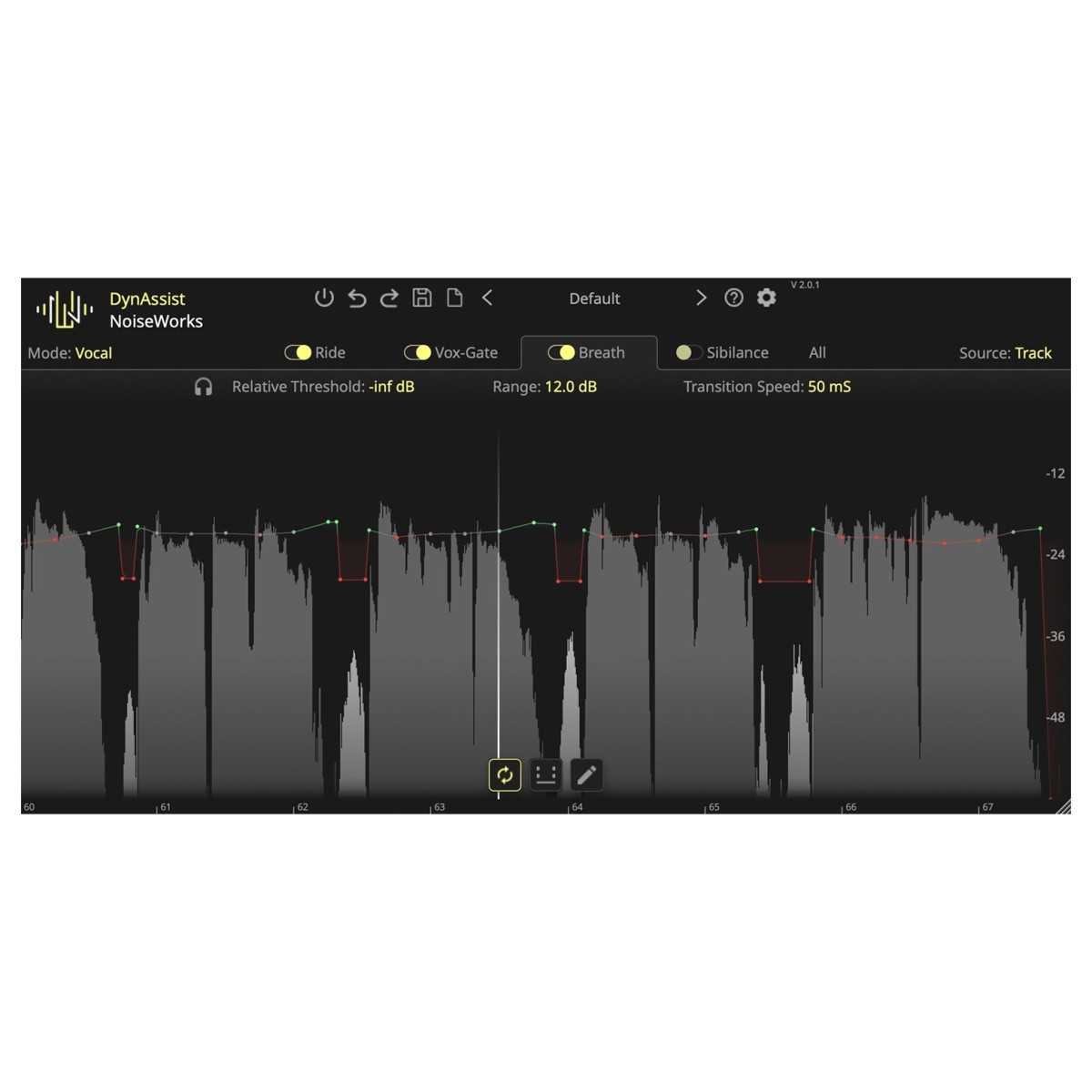
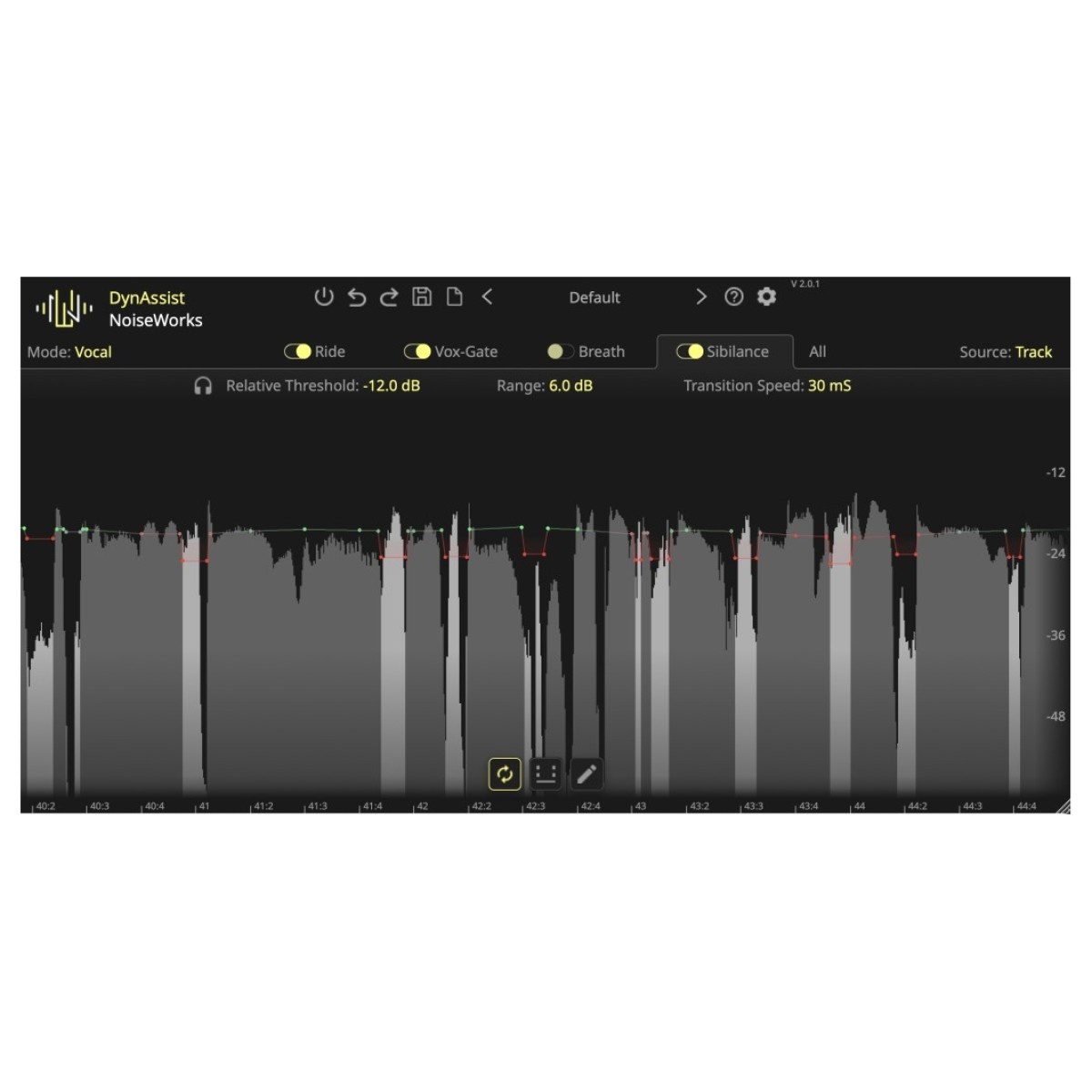
Präzise Atem- und Zischlautkontrolle
Die Atem- und Zischlauterkennung in DynAssist ist präziser als bei Standardlösungen und reduziert den Bedarf an manuellen Bearbeitungen. Atemgeräusche werden automatisch ausgeglichen, während harte "S"-Laute ohne Beeinträchtigung der Klarheit gebändigt werden. Visuelles Feedback auf der Benutzeroberfläche macht es einfach, Änderungen zu verfolgen, wobei Atemgeräusche dunkelgrau und Zischlaute hellgrau hervorgehoben werden. Für eine maximale Kontrolle können Sie die Automatisierung auch manuell feineinstellen.
Bewertungen
"Stellen Sie sich vor, vier oder fünf Ihrer bevorzugten Vocal-Plug-ins wären in einem einzigen Kraftpaket vereint, das Ihnen vollständige Kontrolle und kompromisslose Qualität bietet. Eine unübertroffene Zeitersparnis. Eines, das wirklich alles kann!" - Nikolas Giannulidis (Produzent & Songwriter - Martin Garrix, Tyga, Chris Brown, Nelly)
"Mit DynAssist habe ich endlich ein Plugin, das mir eine Menge Zeit spart und mir trotzdem 100 Prozent Kontrolle über alles gibt, was eine seltene Kombination ist!" - Kalli Bianco (Produzent & Songwriter - Apache, Nico Santos, Kontra K, Lorendana)
"Arbeitet schnell und zuverlässig und spart tonnenweise Zeit mit beeindruckenden Ergebnissen." - Niklas Neumann (Ingenieur - Bones MC, Raf Camora, Capital Bra, Bausa, Apache)
Merkmale
- Der schnellste Weg zu präzisen und ausgewogenen Vocals in Ihren Mischungen
- Nutzt die ARA-Kommunikation zwischen Plugin und DAW, um Ihren Track offline zu analysieren
- Das Modul Vocal Ride nutzt eine unendliche Vorausschau, um Ihre Vocals perfekt auszugleichen, und ist in der Lage, sich an einen Ziel-Loudness-LUFS-Pegel anzupassen
- Eine Latenz von 0 ms sorgt dafür, dass das Modul Vocal Ride keine Pump-Artefakte erzeugt und Ihren Workflow aufrechterhält
- KI-gesteuertes intelligentes Vocal Gate basiert auf der Stimmaktivität und entfernt Stille und Pausen automatisch, ohne dass ein manueller Schwellenwert eingestellt werden muss, ohne den Anfang und das Ende von Audioclips abzuschneiden
- Die ultrapräzise Atemerkennung macht die manuelle Bearbeitung von Atemgeräuschen überflüssig, da alle Atemclips automatisch nivelliert werden.
- Das Modul zur Erkennung von Zischlauten erkennt und gleicht Zischlaute aus, die den von Ihnen eingestellten Schwellenwert überschreiten.
- Perfekt für Podcasts, Dialoge und natürlich Gesangsdarbietungen
Spezifikationen
- Betriebssystem:
- Mac: MacOS 12.0 und neuere Versionen
- Windows: Windows 10
- CPU:
- Mac: Native Unterstützung für M1/M2
- Windows: mindestens Intel Core i5/i7 4. Generation
- Format:
- Mac: VST-3, AU, AAX
- Windows: VST-3, AAX
- Produkt-Code: 1246-3403